AI-Powered Resume Optimization Platform
- Next.js 16
- React 19
- TypeScript
- Node.js
- Claude API
- GPT-4
- PostgreSQL / pgvector
- Hugging Face
- TanStack Query
- TanStack Router
- AWS
- Docker
The core flow, end to end
Discover, triage, tailor, track — then back to discover with a sharper resume. Each screen below is the real product UI, running live.
Score every job against your resume
Live ATS postings, ranked not by recency but by how well each one matches the resume you picked.
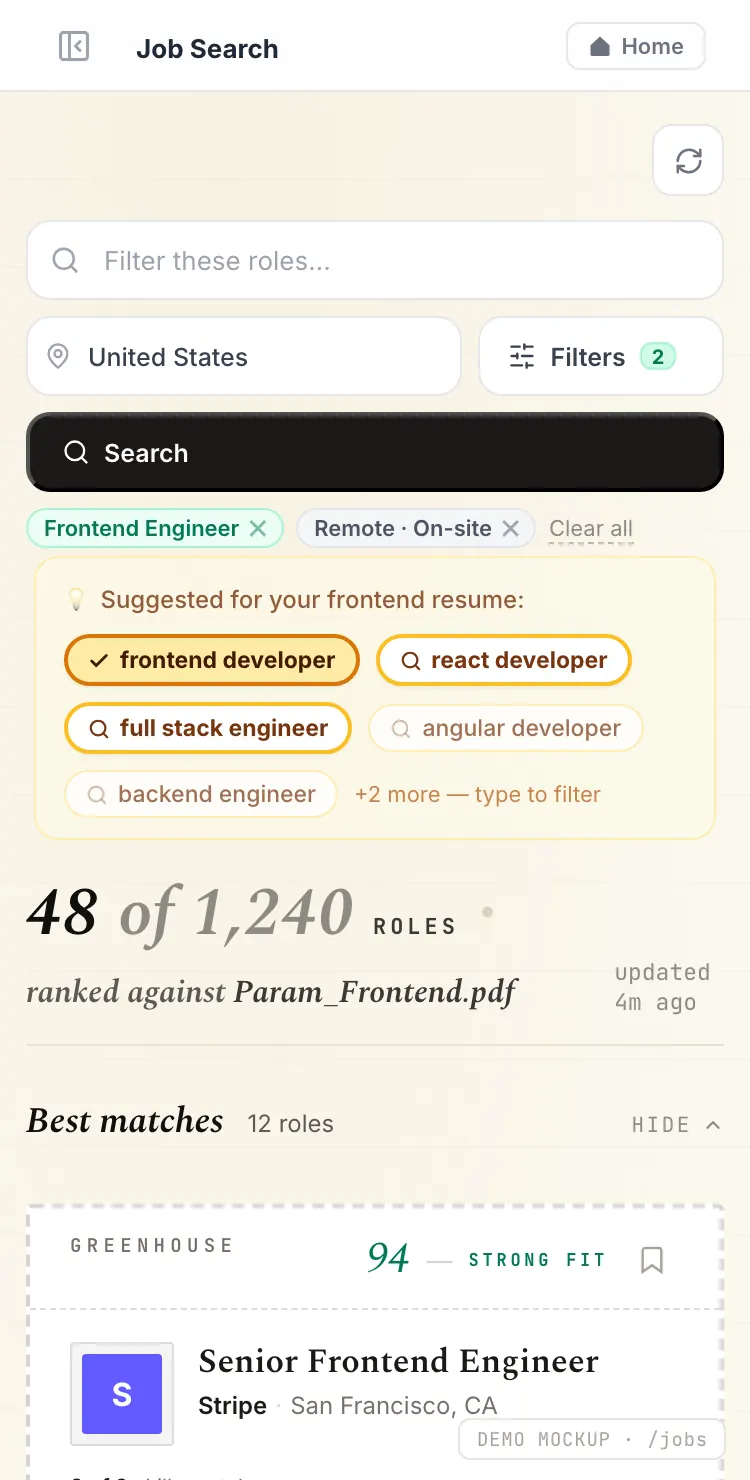
Hybrid retrieval does the ranking
pgvector semantic search, full-text search, and pg_trgm fuzzy matching on PostgreSQL combine into one match score per posting.
Skill overlap, made literal
Every card shows which of the job’s skills the resume already covers — no guessing why a job ranked where it did.
A pipeline, not a bookmark list
Saved jobs flow through lifecycle buckets so you always know which roles are ready and which need attention.
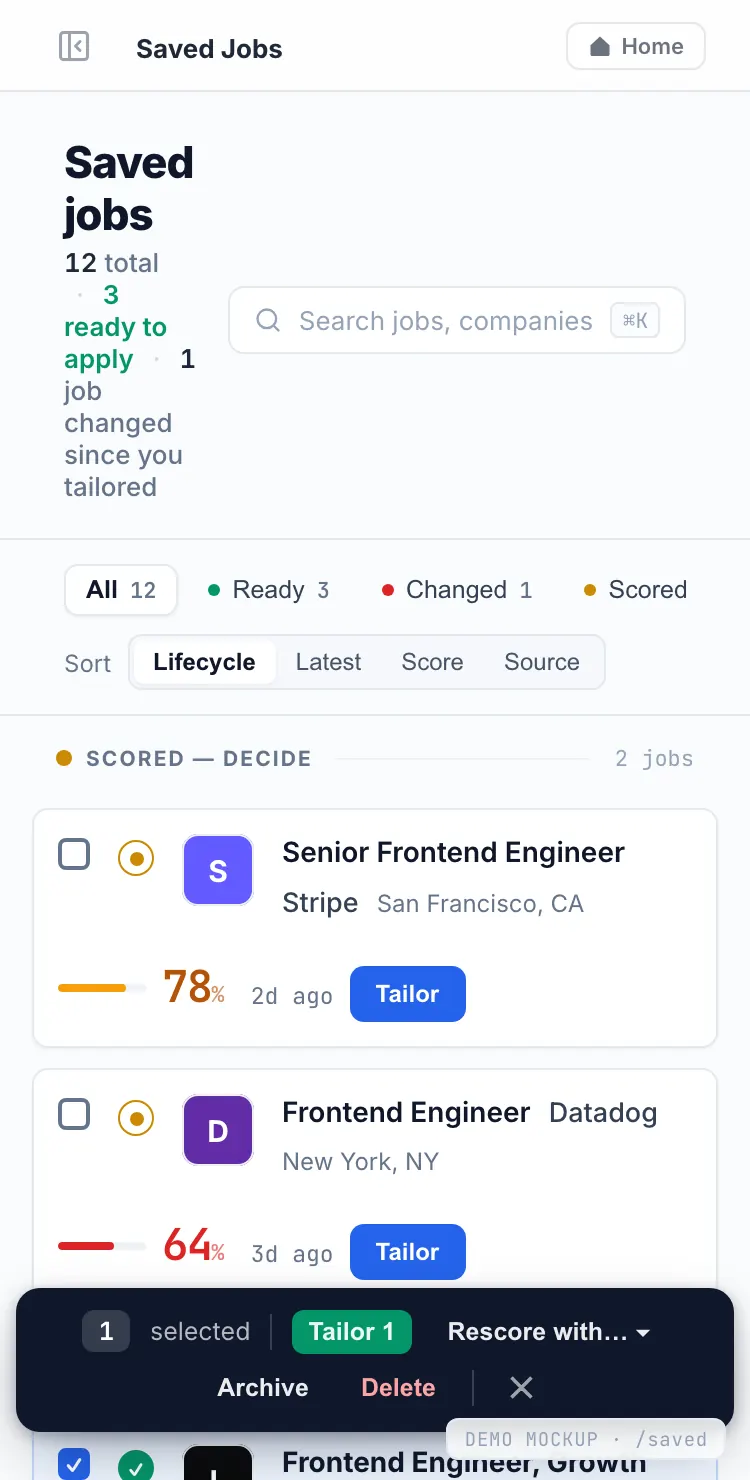
Entity Lock keeps it honest
Dates, employer names, and verified numbers are pinned before the model sees them — it can rephrase, but it can’t invent.
Score lift on every row
Each saved role carries the value tailoring added, so triage decisions are grounded in a number.
The takeover where the work happens
Open a job and the app goes full-screen — the tailored resume center stage, every score one glance away.
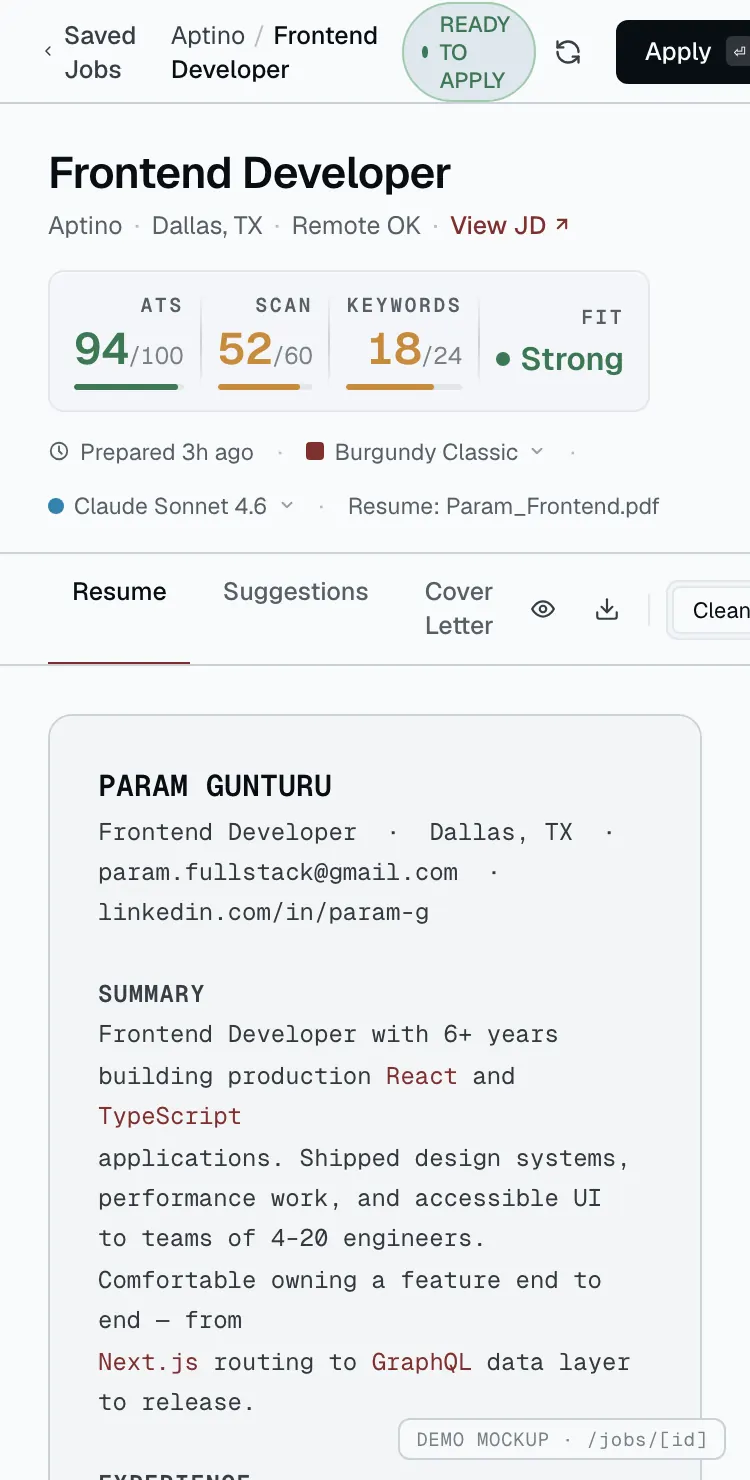
A multi-stage analysis pipeline
Node.js and TypeScript route the rewrite through Claude and GPT-4 across distinct analysis stages.
Progress streams as it runs
Real-time SSE surfaces each stage of the analysis live, instead of a spinner that hides the work.
Every application on one board
Once a resume goes out, the application lands here — status, score, and notes in a single scannable row.
The loop closes here
Outcomes feed back into discovery — every tracked application sharpens the next round of matching.
Regression-tested every change
A Vitest eval harness with 1,300+ assertions runs every change against 17 paired resume-and-JD samples.
Faithful product screens · interactive on hover, or open any frame full screen.
The problem
Tailoring, without the fabrication
Most AI résumé tools hallucinate. They invent skills, fabricate metrics, and slip in keyword-stuffed phrases that fall apart the moment an interviewer asks a follow-up. The output looks fluent until it has to defend itself.
Resume Studio is built on the opposite premise: tailoring means reframing what's already true about you for a specific posting — not inventing a person you aren't. That premise has to be enforced architecturally, not asked for politely in a prompt.
The architecture has three load-bearing pieces. A two-pipeline split puts heuristic scoring on the fast user-facing path ($0 per job card, runs in milliseconds) and reserves LLM cost for deliberate tailoring (~$0.46, gated by explicit user intent). An entity-locking preprocessing layer pins dates, employer names, role titles, and verified numbers as immutable scaffold the writer model never sees as mutable text. A 1,300+ assertion Vitest eval harness gates every pipeline change in CI against seventeen paired résumé-and-JD samples spanning engineering, devops, data, AI, finance, healthcare, and legal — so “improving” a prompt can't silently degrade output quality on résumé types I don't hand-test.
Tailoring means reframing what's already true about you for a specific job — not inventing a person you aren't.
Key decisions
Cost-control, reliability, and routing — by design
The hard problems in an AI résumé product aren't writing prompts. They're keeping LLM cost bounded as usage scales, preventing hallucination structurally (not by asking nicely), and routing each phase to the model that actually fits its workload. Three architectural choices that did the load-bearing.
Two pipelines: $0 scoring, $0.46 tailoring
Most AI résumé tools collapse scoring and tailoring into a single LLM call per interaction. That's slow on the user-facing job board and unsustainable at scale. Resume Studio splits them: a heuristic scoring pipeline runs at $0 on every job card (parses the posting, computes coverage % and evidence scores against the chosen résumé, returns 0–100 in milliseconds with no LLM call). The ~$0.46 LLM tailoring pipeline only runs when the user explicitly clicks “Tailor for this job”.
THE CATCH · Two codebases and two quality bars to maintain. In exchange, the job board UX stays fast and free, and LLM cost is bounded by deliberate user intent.
Entity-locking as scaffold, not prompt
Telling a model “don't change the job title” via prompt is unreliable at production scale and silent when it fails. Resume Studio pins dates, employer names, role titles, and verified numbers in a preprocessing pass as immutable struct fields that the renderer composes into the final document — the writer model never sees them as mutable text. The writer can rephrase a bullet's tense or emphasis freely; it cannot rewrite “Senior Software Engineer” to “Senior Software Architect” because that string isn't part of what it generates.
THE CATCH · Extra preprocessing and a stricter renderer contract. In exchange, the class of hallucination that takes down every other AI résumé tool is structurally impossible here.
Per-phase provider routing across model tiers
Different phases of the pipeline have different workloads. Anthropic's Sonnet-tier model writes the user-visible bullets and summary, where quality matters most. Haiku-tier handles scoring and critique, where structured judgment at low latency wins. OpenAI's GPT-4.1-mini handles cover letter generation, where format-following on long-form output is the workload. Cost is tracked per phase per provider so routing can be re-evaluated as model pricing changes.
THE CATCH · Three model integrations, three retry policies, three sets of model-version pinning. In exchange, each phase runs on the model that fits its workload, and per-tailor cost lands ~$0.46 instead of multiples higher.
What I built
Entire product, end to end
Frontend in Next.js 16 + React 19 with TanStack Router for typed routes and TanStack Query for server state. Backend in Node.js + Express with Prisma against a PostgreSQL (Neon) instance carrying both pgvector and tsvector extensions. The cost-control architecture is the part I'm most proud of: a heuristic scoring pipeline at $0 per job card, a $0.46 tailoring pipeline gated by explicit user intent, a Postgres-backed per-phase response cache that makes re-tailoring against the same posting essentially free, and a smart-skip + stale-while-revalidate layer that brought per-cold-search cost from $1.33 to $0.06–0.13.
Job ingestion fans out across eleven sources — direct ATS APIs (Greenhouse, Ashby, Lever, Workable), aggregators (Adzuna, Remotive), and external scrapers for LinkedIn, Indeed and Glassdoor. Hybrid retrieval on PostgreSQL combines BM25-style full-text via tsvector, pgvector cosine similarity on locally-generated 384-dim sentence embeddings, and pg_trgm fuzzy matching for typo tolerance — unioned, deduplicated by title+company hash, and rank-normalized per-pool before merging. Real-time SSE streaming surfaces multi-stage tailor progress phase-by-phase as it runs.
Every pipeline change runs against a Vitest eval harness — 1,300+ assertions across seventeen paired résumé-and-JD samples — and CI fails on regression. Final output renders through a Typst-based DOCX pipeline. Deployed on AWS with Docker and GitHub Actions.
- Next.js 16 + React 19 frontend with TanStack Router (typed routes) and TanStack Query (server state)
- Node.js + Express backend, Prisma ORM, PostgreSQL on Neon
- Hybrid retrieval on PostgreSQL: pgvector (semantic) + tsvector (full-text) + pg_trgm (fuzzy)
- Locally-hosted sentence-transformer for 384-dim embeddings — résumé data never leaves the server
- Two LLM pipelines: $0 heuristic ATS scoring and ~$0.46 multi-stage tailoring routed per-provider
- Entity-locking preprocessing + Vitest eval harness (1,300+ assertions, regression-gated in CI)
- Job ingestion across 11+ sources: direct ATS APIs (Greenhouse, Ashby, Lever, Workable), aggregators, external scrapers
- Cost-control: smart-skip, stale-while-revalidate, Postgres-backed LLM phase cache
- Real-time SSE streaming for phase-by-phase tailor progress
- Typst-based DOCX renderer for final downloadable output
- AWS deployment with Docker and GitHub Actions CI/CD
Drop me a line.
Email is fastest — I read every one. Glad to hear from teams shipping in regulated, high-traffic, or AI-heavy spots.